למה אופי Telugu הוא Bricking התקנים אפל
Apple כבר נתקל באגי כמה חודשים. עכשיו יש לנו באג חדש, רציני בפונקציונליות עיבוד הטקסט ב- iPhones. הבאג מופעל על ידי תו Telugu אחד שיכול לגרום ל- iPhone להיכנס לולאה אתחול בלתי שביר רק על ידי קבלת הודעה המכילה את התו. בואו להתעמק מדוע דמות אחת יכולה לגרום לבעיות גדולות כאלה עם iOS.
הערה: תיקון באג טלוגו זמין בגירסה העדכנית ביותר של iOS (11.2.6). אם התו Telugu נעול את היישום או המכשיר, לשחזר את iPhone דרך iTunes ועדכן את הגרסה העדכנית ביותר של iOS. אם ה- iPhone שלך תקוע בלולאת אתחול, ייתכן שיהיה עליך לשים אותו במצב עדכון קושחה (DFU) של מכשיר כדי לקבל את iTunes לזהות אותו. בסיום, שחזר את המכשיר מהגיבוי האחרון שלך, שאותו יצרת.
מה זה Telugu?

Telugu היא שפה מדוברת וכתוב בחלקים של הודו, במיוחד את מדינות אנדרה פראדש, Telangana, וכן בעיר ינאם. בדומה לשפות רבות המבוססות על סקריפטים, כגון ערבית ותסריטים ברהמיים אחרים, Telugu משתמשת בכמה תכונות מיוחדות של התווים Unicode כדי להציג את התווים שלה על מסך המחשב.
בעוד שרוב האותיות הלטיניות מיוצגות על ידי נקודת קוד Unicode בודדת של 8 סיביות עבור תאימות ASCII (לדוגמה, האות A קיימת בנקודת קוד Unicode U+0041, המיוצגת בינארי על ידי 01000001 ), שפות הכתובות ב- script או ב- אותיות לטיניות בדרך כלל משלבות יותר מנקודת קוד Unicode אחת לייצוג התווים שלהן.
הדבר נכון במיוחד עבור שפות, כמו Telugu, המשלבות את גרסאות השפות של השפות באשכולות. שלא כמו הליגטורות הסגנוניות של האנגלית, הקשר בין כל אות טלוגו הוא בעל חשיבות בלשנית. כדי להתאים את זה, Unicode כוללת מערכת מורכבת של צירוף תווים, כל מיוצג על ידי נקודת הקוד שלהם, אחד לשני.
בהתחשב במספר מוחלט של נקודות קוד Unicode, זה יכול ליצור מגוון אינסופי כמעט. נקודות אלה משתלבות יחד כדי להפוך דמות קריא. בדרך זו Unicode לא צריך נקודת קוד Unicode עבור כל מילה Telugu אפשרי. במקום זאת, Unicode משלבת עיצורים של טלוגו, תנועות ותזכורות ("virama") יחד כדי ליצור מילים שמוצגות כמו דמות אחת. כך גם לגבי שפות אחרות עם כללים אורתוגרפיים לליגטורות, כמו ערבית.
מה גורם לקריסה?

נראה שהבעיה קשורה לרוחב אפס (Non-Joiner) (ZWNJ) בנקודת קוד U+200C . ZWNJ מבקש ששתי דמויות סמוכות יוצגו ללא הליגטורה הטיפוסית שלהן. באנגלית, ZWNJ שומר את התווים ff מלהיות מודפס עם חיבור רגיל שלהם ligature, במקום להפריד כל F. אבל כאשר בשילוב עם קבוצה מסוימת של ארבע נקודות קוד Telugu (כל אשר יש לשלב לאשכול יחיד), משום מה iOS לא יכול להציג את התוצאה כראוי.
חלקם משערים כי אפל של סן פרנסיסקו גופן לא יכול להציג את הדמות, בעוד שאחרים אמרו כי תהליך עיבוד ספציפי אפל משתמש הוא אשם. לא משנה מה הסיבה המדויקת, את הניסיון להפוך את אופי גורם התרסקות דרמטית של מה הוא טיוח זה, מתוך הודעות ו WhatsApp כדי קרש קפיצה. נקודות קוד Unicode המרכיבות את התו ("gya" כלומר "ידע") הן למטה:
U+0C1Cja (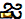 )
)U+0C4Da virama, או סימן diacritic ( )
)U+0C1Enya (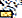 )
)U+200Cרוחב אפס שאינם joinersU+0C3Eaa (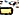 )
)
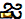 )
) )
)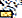 )
)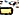 )
)אבל אנחנו לא יכולים אפילו להאשים Zero רוחב Non-Joiner (ZWNJ) לבד. זה משמש גם את emojis משפחתי תמימה (????) ללא כל בעיה. זה נראה שילוב מסוים של כמה נקודות קוד ספציפי ZWNJ. הוספת העלבון לפציעה, זה נראה כמו ZWNJ או אין השפעה מיוחדת על עיבוד על זה אשכול Telugu או שזה אפילו לא צריך להיות שם מלכתחילה.
בעיות ברהמיות אחרות
Telugu היא לא השפה היחידה עם בעיה זו, עם זאת. בנגאלי ודוונגארי, המשתמשים ב- Unicode באופן דומה עבור הסקריפטים הבראמיים שלהם, יש אותה בעיה. מאניש Goregaokar כותב פוסט בבלוג fasctinating מפורט שיוצר את האירוע לקרוס המדויק למטה עוד יותר:
כל רצף
ב דוונגארי, בנגלית, ו Telugu, שם:1.
consonant2הוא סיומת שהצטרף (pstf/vatu)
2.consonant1אינו מכתב יוצר
3.vowelאינה כוללת שני רכיבי גליף
מסקנה: למה זה לא נתפס על ידי אפל?
כדי להבין איך זה באג עבר, אתה צריך לשים את עצמך בנעליים של אפל. בטח, זה שילוב תווים היא לא מילה סופר סתום בשפה הטלוגו. אבל ה- iPhone כולל תמיכה בעשרות שפות. יש ממש מיליארדי שילובים פוטנציאליים ב- Unicode. עם מגוון זה הרבה, בדיקות משמעותיות עבור באגים Unicode לפני שחרור תעשה עדכונים תוכנה רגילה בעצם בלתי אפשרי.
עם זאת, השגיאה לא צריך לגרום נזק זה הרבה. טלפונים לא צריך לקבל לבנים על סמך התוכן של הודעת טקסט. בעוד בדיעבד הוא 20/20, נראה כמו טיוח הדמות כמו תיבת סימון שאלה ( ) היה טוב יותר מתרסק קרש קפיצה.
![עיבוד תמונה אצווה קל עם ImBatch [Windows]](http://moc9.com/img/imbatch-installation.jpg)